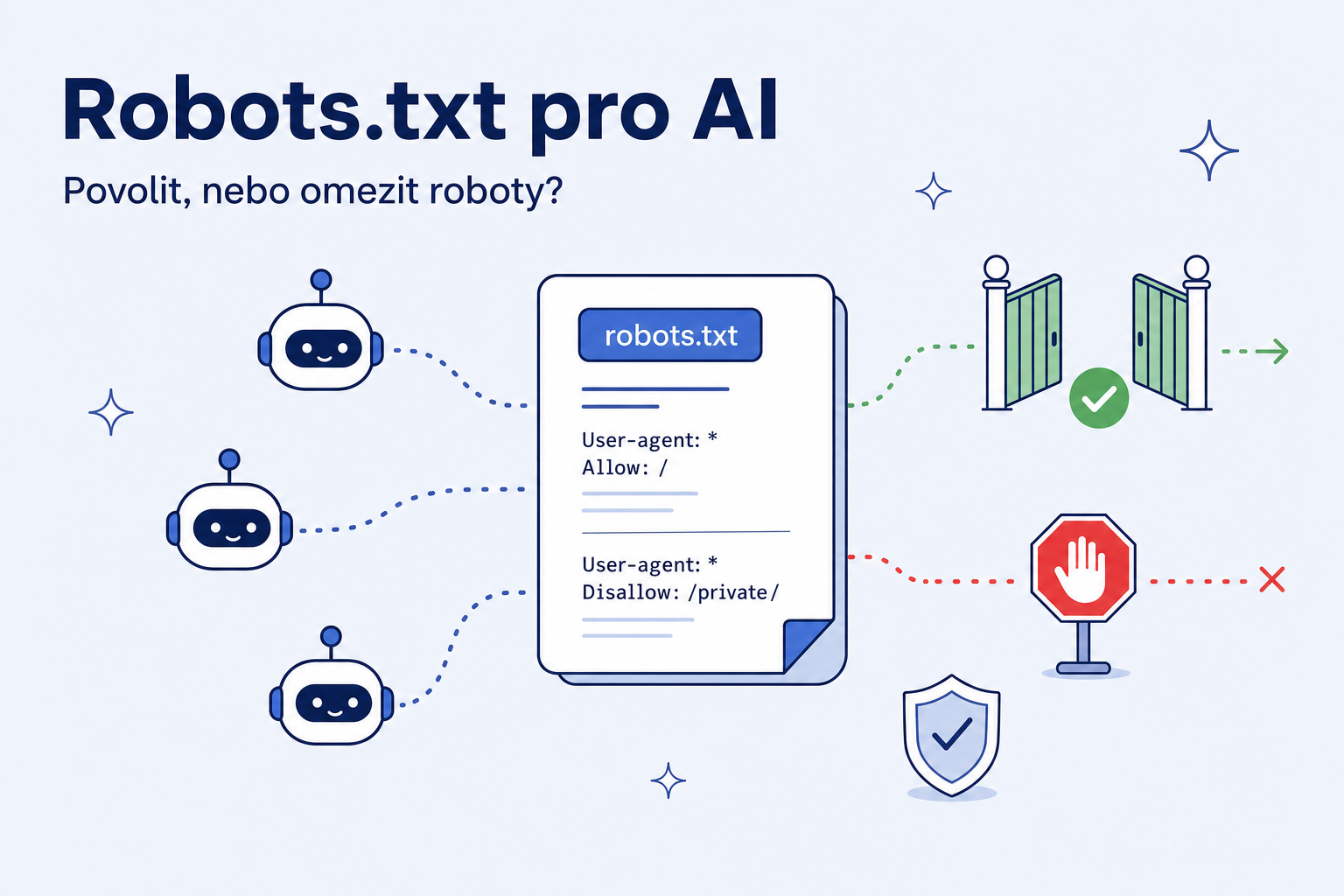
AI roboti a robots.txt: kdo chodí na web a jak ho řídit
Přístup AI robotů řídíte hlavně přes soubor robots.txt — veřejný textový soubor v kořeni webu, kterým robotům dáváte pravidla pro procházení. Tento návod ukazuje, jak nastavit robots.txt pro AI roboty: kteří roboti dnes web navštěvují, jak je povolit kvůli citacím, jak omezit jejich využití k tréninku a kde robots.txt přestává stačit.
Pozor na záměnu: tohle není o vypínání Google AI Overviews ve výsledcích (to řeší samostatný návod). Tady jde o přístup robotů k webu napříč AI službami.
Kteří AI roboti a řídicí tokeny se v robots.txt řeší
Velcí hráči mají víc robotů s různým účelem — jiný pro trénink, jiný pro vyhledávání, jiný pro načtení stránky, když se na ni uživatel zeptá:
| Robot | Provozovatel | Účel |
|---|---|---|
| GPTBot | OpenAI | trénink modelů |
| OAI-SearchBot | OpenAI | vyhledávání a citace v ChatGPT |
| ChatGPT-User | OpenAI | načtení stránky na vyžádání uživatele |
| ClaudeBot | Anthropic | trénink modelů |
| Claude-SearchBot | Anthropic | vyhledávání |
| Claude-User | Anthropic | načtení na vyžádání |
| PerplexityBot | Perplexity | procházení pro indexaci a odpovědi (dle dokumentace provozovatele) |
| Google-Extended | řídicí token pro využití obsahu v generativních AI službách Google, např. Gemini (ne klasická indexace) | |
| CCBot | Common Crawl | tvorba veřejného datasetu webu; data mohou být využita i pro trénink modelů |
Konkrétní názvy se mění — aktuální seznam najdete v dokumentaci jednotlivých služeb.
Chci zvýšit šanci na citace: pusťte vyhledávací roboty
Pokud chcete zvýšit šanci, že vás AI nástroje najdou a ocitují, nechte projít hlavně vyhledávací roboty. V robots.txt v kořeni webu:
# Pustit AI roboty pro vyhledávání a citace
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ChatGPT-User
Allow: /Když robota žádné pravidlo nezakazuje, většinou má přístup i bez explicitního Allow — uvedení je hlavně pro přehlednost. Povolení robotů ale samo o sobě citace nezajistí; jen odstraňuje technickou překážku, aby se obsah mohl dostat do vyhledávacích a odpovědních vrstev. Tahle vrstva navazuje na SEO pro ChatGPT a patří do širšího AI SEO auditu.
Nechci obsah do tréninku: omezte tréninkové roboty
Pokud chcete dát najevo, že si nepřejete využití obsahu k tréninku modelů, omezte tréninkové roboty (jde o signál pro slušné provozovatele, ne o vynutitelnou záruku):
# Omezit roboty pro trénink modelů
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /Rozlišujte přitom roboty pro trénink a pro vyhledávání: můžete zakázat trénink (GPTBot) a přitom nechat projít vyhledávání (OAI-SearchBot), abyste zůstali citovatelní. Blokace všeho najednou citovatelnost obětuje.
Google-Extended řešte zvlášť
Google-Extended je častý zdroj nedorozumění. Není to klasický indexovací robot, ale řídicí token, kterým podle dokumentace Googlu ovlivňujete, jestli může být obsah webu využit pro generativní AI služby Google (například Gemini Apps a Vertex AI). Podle dokumentace jeho blokace neřídí běžné procházení, indexaci ani pozice v Google Search — to zajišťuje klasický Googlebot. Google-Extended tedy můžete zakázat, aniž tím přímo měníte viditelnost v Google Search.
robots.txt je žádost, ne zámek
Tohle je nejdůležitější věc, kterou si odnést: robots.txt je dobrovolná žádost, ne technická zábrana. Slušní roboti pravidla respektují, ale není to vynutitelné:
- Někteří roboti pravidla ignorují — například Bytespider podle veřejně citovaných dat z roku 2024 patřil mezi nejaktivnější AI roboty a pravidla robots.txt často nedodržoval.
- Pro tvrdší blokování řešte zásah na serveru, firewallu nebo CDN. Samotný user-agent jde podvrhnout, proto ho kombinujte s ověřením IP rozsahů, omezením frekvence a sledováním logů.
- Nedávejte do robots.txt citlivé nebo neveřejné URL jako náhradu zabezpečení — soubor je veřejný a
Disallownebrání přímému přístupu na stránku.
robots.txt berte jako první vrstvu pro slušné roboty, ne jako záruku.
Jak ověřit nastavení
Po úpravě robots.txt zkontrolujte:
Kontrola nastavení robots.txt
- Soubor je dostupný otevřete https://vasedomena.cz/robots.txt — musí vracet HTTP 200 a obsahovat vaše pravidla.
- Správná skupina pravidel konkrétní User-agent má u běžných parserů přednost před obecným User-agent: *; chování otestujte.
- Sledujte logy serveru po nasazení ověřte, že se roboti chovají podle očekávání.
- Hlídejte tvrdou blokaci u blokování sledujte odpovědi 403/429 a falešně zablokované roboty.
A co llms.txt?
Často se zmiňuje soubor llms.txt. Berte ho s rezervou: je to návrh formátu, který popisuje obsah webu pro AI, ne nástroj na řízení přístupu. Podle dostupných informací ho velcí roboti k roku 2026 spolehlivě nepoužívají. Pro řízení přístupu se proto spoléhejte na robots.txt a server, ne na llms.txt.
Časté chyby
Zablokovat všechny AI roboty
Plošná blokace obětuje i roboty pro vyhledávání, takže vás AI přestanou citovat.
Fix: Pusťte aspoň vyhledávací roboty.
Blokovat Google-Extended kvůli pozicím
Google-Extended ovlivňuje jen generativní AI služby Google, ne běžné vyhledávání.
Fix: Na pozice v Google Search nemá vliv.
Spoléhat na robots.txt jako na zámek
Neslušné roboty robots.txt nezastaví.
Fix: Tvrdé blokování řešte na serveru nebo firewallu.
Brát llms.txt jako řízení přístupu
llms.txt není nástroj na blokování.
Fix: Na blokování použijte robots.txt a server.
Co dál: nastavte to v rámci celého webu
Přístup robotů je jen jedna vrstva AI viditelnosti. Jak na ni navázat strukturou, strukturovanými daty a citovatelným obsahem, shrnuje praktický checklist SEO pro AI.
Když to chcete převést na konkrétní šablony pro celý web, pomůže AI SEO Wireframe Pack za 1 490 Kč. Pokud chcete přístup robotů i zbytek webu prověřit na míru, dává smysl AI SEO audit za 9 990 Kč.